When would you want to use it?
Deepchecks is an open-source library that you can use to run a variety of data and model validation tests, from data integrity tests that work with a single dataset to model evaluation tests to data drift analyses and model performance comparison tests. All this can be done with minimal configuration input from the user, or customized with specialized conditions that the validation tests should perform. Deepchecks works with both tabular data and computer vision data (currently in beta). For tabular, the supported dataset format ispandas.DataFrame and the supported model format is sklearn.base.ClassifierMixin. For computer vision, the supported dataset format is torch.utils.data.dataloader.DataLoader and supported model format is torch.nn.Module.
You should use the Deepchecks Data Validator when you need the following data and/or model validation features that are possible with Deepchecks:
- Data Integrity Checks for tabular or computer vision data: detect data integrity problems within a single dataset (e.g. missing values, conflicting labels, mixed data types etc.).
- Data Drift Checks for tabular or computer vision data: detect data skew and data drift problems by comparing a target dataset against a reference dataset (e.g. feature drift, label drift, new labels etc.).
- Model Performance Checks for tabular or computer vision data: evaluate a model and detect problems with its performance (e.g. confusion matrix, boosting overfit, model error analysis)
How do you deploy it?
The Deepchecks Data Validator flavor is included in the Deepchecks ZenML integration, you need to install it on your local machine to be able to register a Deepchecks Data Validator and add it to your stack:How do you use it?
The ZenML integration restructures the way Deepchecks validation checks are organized in four categories, based on the type and number of input parameters that they expect as input. This makes it easier to reason about them when you decide which tests to use in your pipeline steps:- data integrity checks expect a single dataset as input. These correspond one-to-one to the set of Deepchecks data integrity checks for tabular and computer vision data
- data drift checks require two datasets as input: target and reference. These correspond one-to-one to the set of Deepchecks train-test checks for tabular data and for computer vision.
- model validation checks require a single dataset and a mandatory model as input. This list includes a subset of the model evaluation checks provided by Deepchecks for tabular data and for computer vision that expect a single dataset as input.
- model drift checks require two datasets and a mandatory model as input. This list includes a subset of the model evaluation checks provided by Deepchecks for tabular data and for computer vision that expect two datasets as input: target and reference.
- instantiate, configure and insert one or more of the standard Deepchecks steps shipped with ZenML into your pipelines. This is the easiest way and the recommended approach, but can only be customized through the supported step configuration parameters.
- call the data validation methods provided by the Deepchecks Data Validator in your custom step implementation. This method allows for more flexibility concerning what can happen in the pipeline step, but you are still limited to the functionality implemented in the Data Validator.
- use the Deepchecks library directly in your custom step implementation. This gives you complete freedom in how you are using Deepchecks’ features.
Warning! Usage in remote orchestrators
The current ZenML version has a limitation in its base Docker image that requires a workaround for all pipelines using Deepchecks with a remote orchestrator (e.g. Kubeflow, Vertex). The limitation being that the base Docker image needs to be extended to include binaries that are required byopencv2, which is a package that Deepchecks requires.
While these binaries might be available on most operating systems out of the box (and therefore not a problem with the default local orchestrator), we need to tell ZenML to add them to the containerization step when running in remote settings. Here is how:
First, create a file called deepchecks-zenml.Dockerfile and place it on the same level as your runner script (commonly called run.py). The contents of the Dockerfile are as follows:
dockerfile are relative to where the pipeline definition file is. Read the containerization guide for more details:
The Deepchecks standard steps
ZenML wraps the Deepchecks functionality for tabular data in the form of four standard steps:- DeepchecksDataIntegrityCheckStep: use it in your pipelines to run data integrity tests on a single dataset
- DeepchecksDataDriftCheckStep: use it in your pipelines to run data drift tests on two datasets as input: target and reference.
- DeepchecksModelValidationCheckStep: class DeepchecksModelDriftCheckStep(BaseStep): use it in your pipelines to run model performance tests using a single dataset and a mandatory model artifact as input
- DeepchecksModelDriftCheckStep: use it in your pipelines to run model comparison/drift tests using a mandatory model artifact and two datasets as input: target and reference.
- the type and number of input artifacts are different, as mentioned above
-
each step expects a different enum data type to be used when explicitly listing the checks to be performed via the
check_listconfiguration attribute. See the zenml.integrations.deepchecks.validation_checks module for more details about these enums (e.g. the data integrity step expects a list ofDeepchecksDataIntegrityCheckvalues).
SuiteResult object that contains the test results:
check_list argument to the step configuration:
DeepchecksDataIntegrityCheckStepParams step configuration also allows for additional keyword arguments to be supplied to be passed transparently to the Deepchecks library:
dataset_kwargs: Additional keyword arguments to be passed to the Deepcheckstabular.Datasetorvision.VisionDataconstructor. This is used to pass additional information about how the data is structured, e.g.:
check_kwargs: Additional keyword arguments to be passed to the Deepchecks check object constructors. Arguments are grouped for each check and indexed using the full check class name or check enum value as dictionary keys, e.g.:
run_kwargs: Additional keyword arguments to be passed to the Deepchecks Suiterunmethod.
check_kwargs attribute can also be used to customize the conditions configured for each Deepchecks test. ZenML attaches a special meaning to all check arguments that start with condition_ and have a dictionary as value. This is required because there is no declarative way to specify conditions for Deepchecks checks. For example, the following step configuration:
The Deepchecks Data Validator
The Deepchecks Data Validator implements the same interface as do all Data Validators, so this method forces you to maintain some level of compatibility with the overall Data Validator abstraction, which guarantees an easier migration in case you decide to switch to another Data Validator. All you have to do is call the Deepchecks Data Validator methods when you need to interact with Deepchecks to run tests, e.g.:Call Deepchecks directly
You can use the Deepchecks library directly in your custom pipeline steps, and only leverage ZenML’s capability of serializing, versioning and storing theSuiteResult objects in its Artifact Store, e.g.:
The Deepchecks ZenML Visualizer
In the post-execution workflow, you can load and render the Deepchecks test suite results generated and returned by your pipeline steps by means of the ZenML Deepchecks Visualizer, e.g.: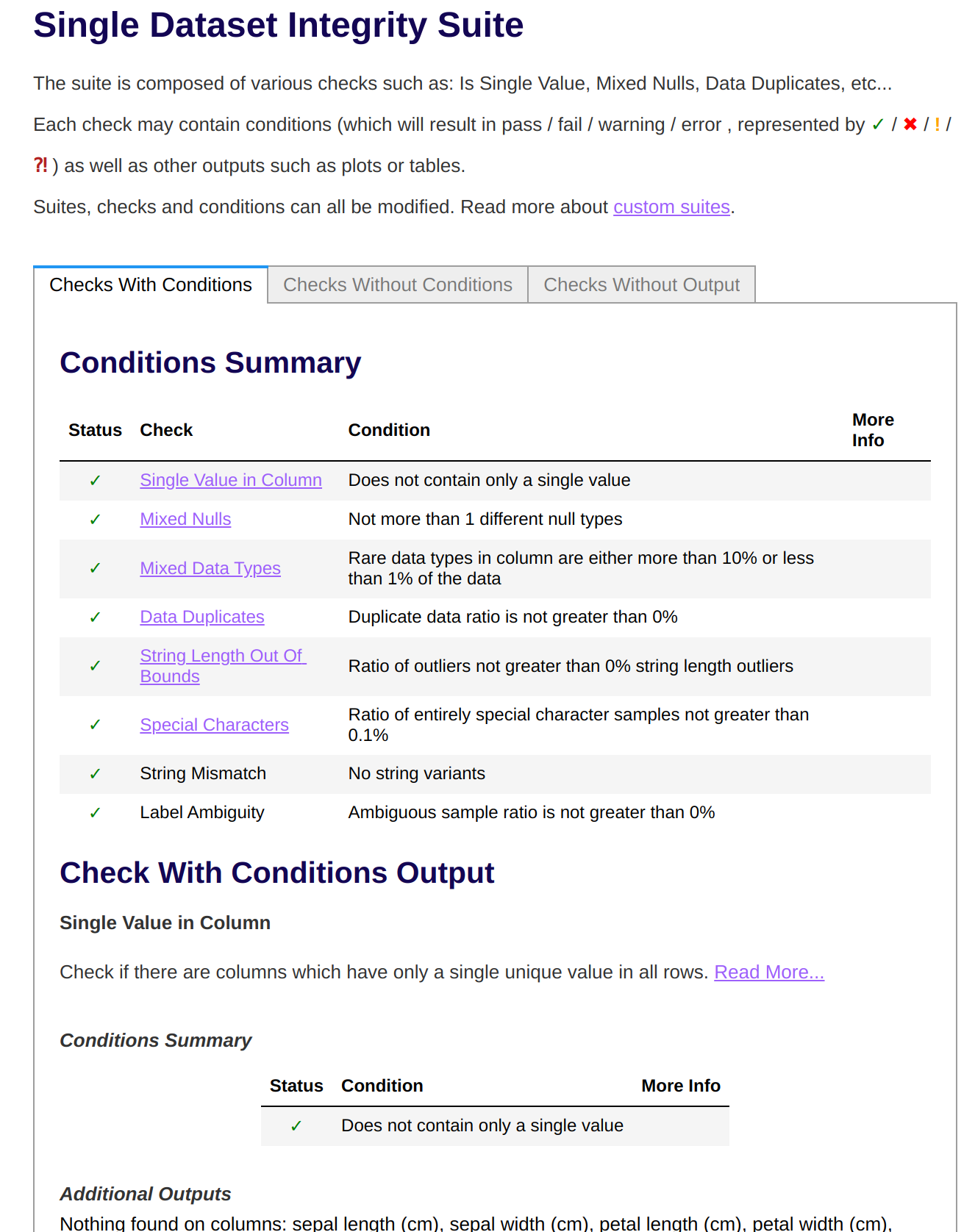 Deepchecks Visualization Example
Deepchecks Visualization Example