- Writing a pipeline to define what happens in your machine learning workflow.
- Configuring a ZenML stack.
- Switching between stacks depending on needs.
- Customizing your stack with different components.
Pipelines and Steps
At its core, ZenML follows a pipeline-based workflow for your data projects. A pipeline consists of a series of steps, organized in any order that makes sense for your use case. Below, you can see three steps running one after another in a pipeline.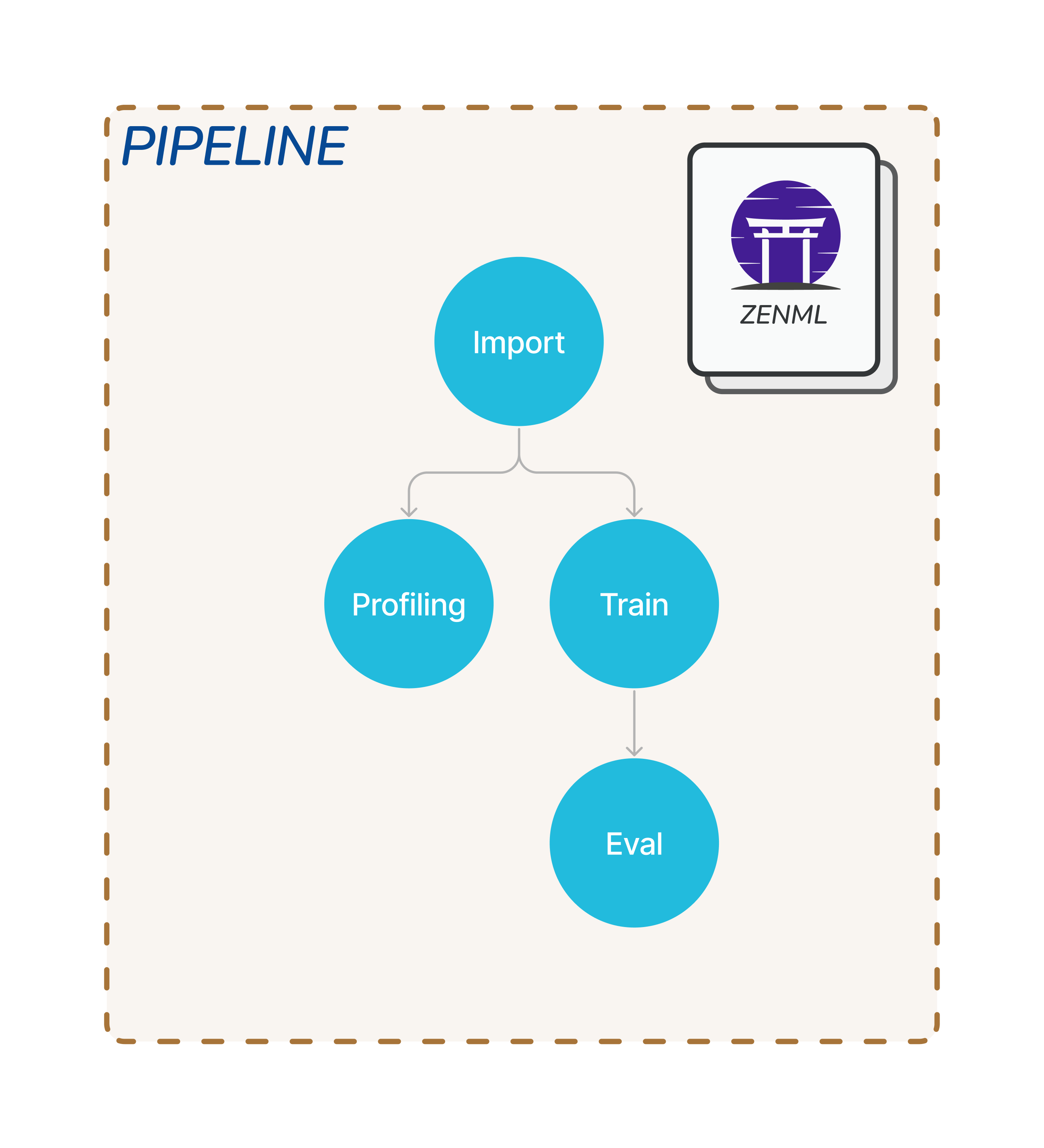
Stacks and Stack Components
A Stack is the configuration of the underlying infrastructure and choices around how your pipeline will be run. For example, you can choose to run your pipeline locally or on the cloud by changing the stack you use. ZenML comes with a default stack that runs locally, as seen in the following diagram: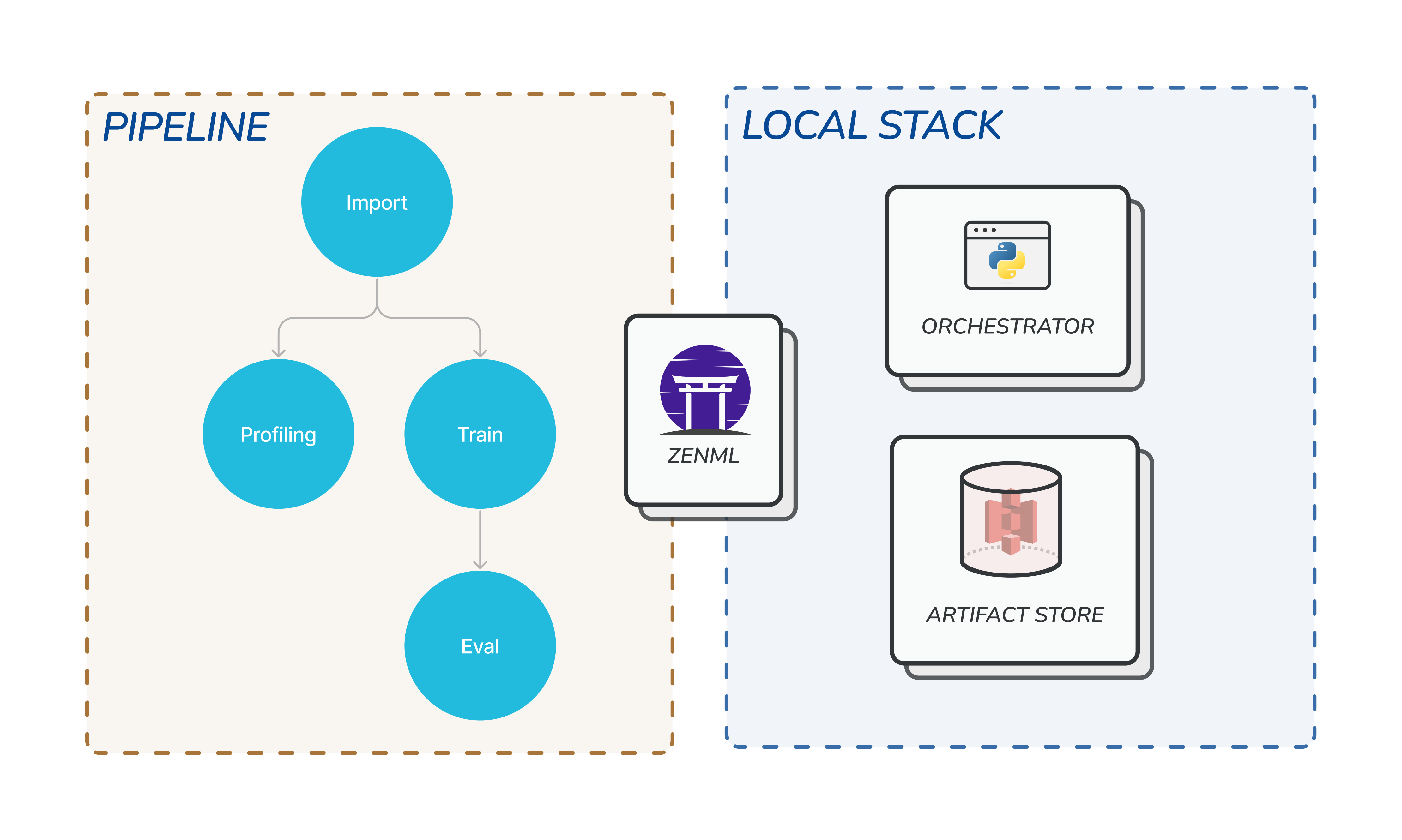
Orchestrator
An Orchestrator is the workhorse that coordinates all the steps to run in a pipeline. Since pipelines can be set up with complex combinations of steps with various asynchronous dependencies between them, the Orchestrator is the component that decides what steps to run, when, and how to pass data between the steps. ZenML comes with a default local orchestrator designed to run on your local machine. This is useful especially during the exploration phase of your project. You don’t have to rent a cloud instance just to try out basic things. Once the pipeline is established you can switch to a full-fledged cloud stack that uses more sophisticated orchestrators like the Airflow or Kubeflow orchestrator. See the list of all orchestrators here.Artifact Store
An Artifact Store is a component that houses all data that pass through the pipeline. Data in the artifact store are called artifacts. These artifacts may have been produced by the pipeline steps, or they may be the data ingested into a pipeline via an importer step. The artifact store houses all intermediary pipeline step results. The fact that all your data inputs and outputs are tracked and versioned in the artifact store allows for extremely useful features like data caching which speeds up your workflow. See the list of all supported artifact stores here.Other Stack Components
We’ve covered the two basic stack components that you will encounter most frequently. They work well on a local machine, but is rarely enough in production. At some point, you might want to scale up your stack to run elsewhere, for example on a cloud with powerful GPUs for training or CPU’s for deployment. ZenML provides many other stack components to suit these use cases. Having these components in your stack supercharges your pipeline for production. For other stack components check out this page.Switching Stacks to Scale Up
We’ve seen how to run a pipeline locally. But that is rarely enough in production machine learning which typically involves cloud infrastructure. What’s really cool with using ZenML is you can easily switch your stack from running on a local machine to running on the cloud with a single CLI command. The rest of the code defining your steps and pipelines stays the same, whether it’s running on a local machine or a cloud infrastructure of your choice. The only change is in the stack and its components. Below is an illustration showing how the same pipeline on a local machine can be scaled up to run on a full-fledged cloud infrastructure by switching stacks. You get all the benefits of using cloud infrastructures with minimal changes in your code.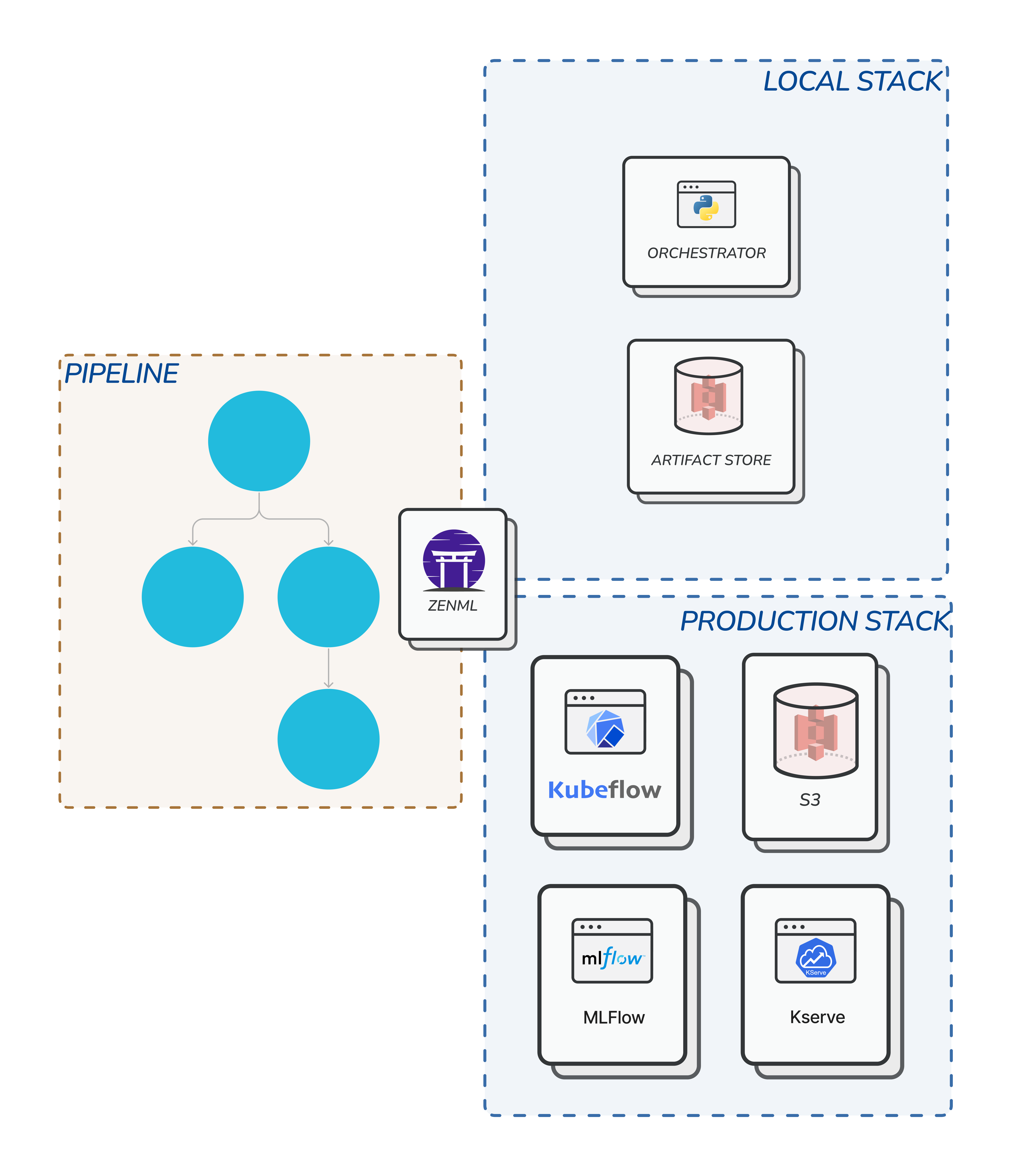
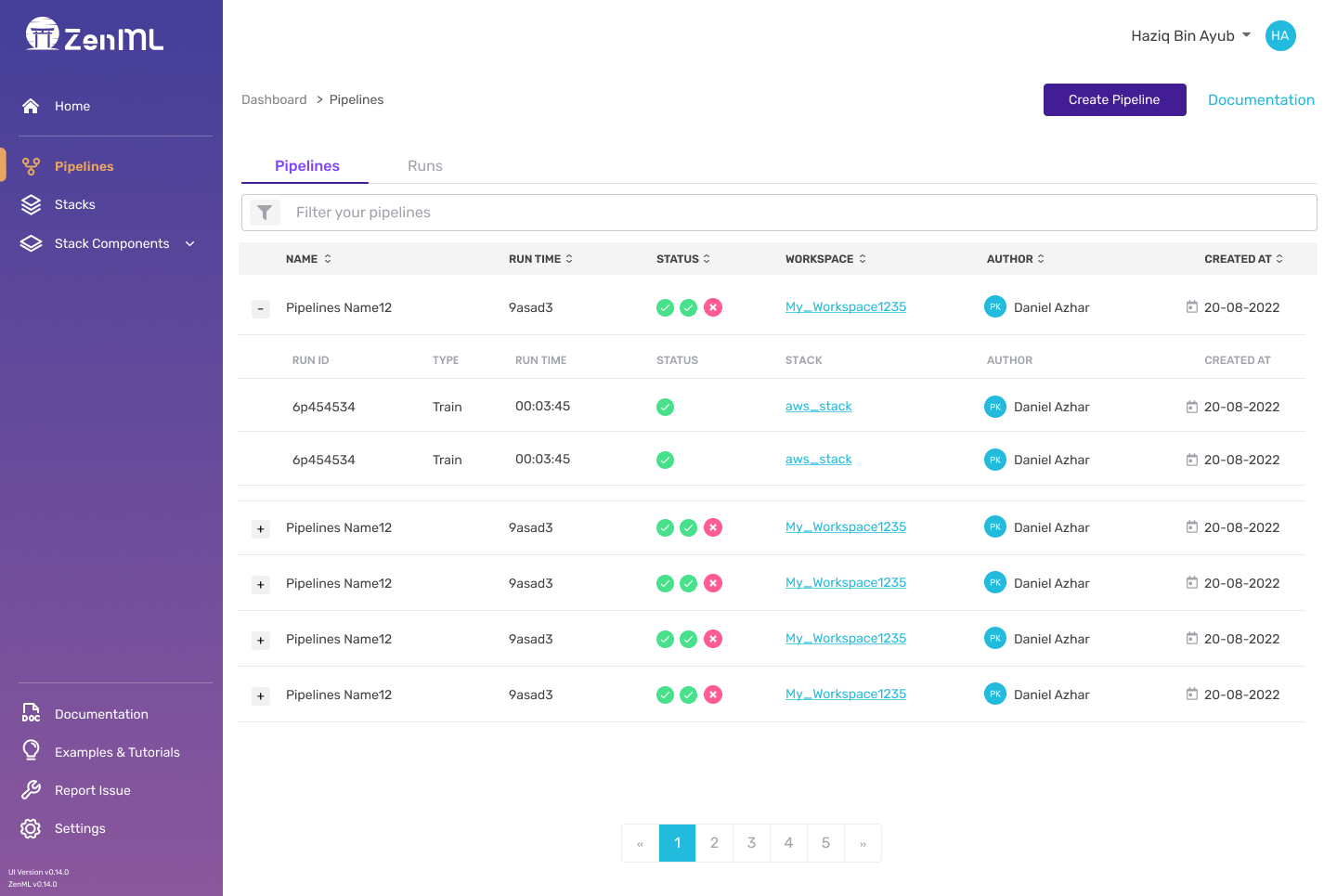
ZenML Server and Dashboard
In order to run stack components that are running on infrastructure on the cloud, ZenML itself needs to deployed to the cloud first, so that it can communicate with these stack components. A ZenML Server keeps track of all the bits of metadata around a pipeline run. It allows you to fetch specific steps from your pipeline run and their output artifacts in a post-execution workflow. With a ZenML server, you are able to access all of your previous experiments with the associated details. This is extremely helpful in troubleshooting.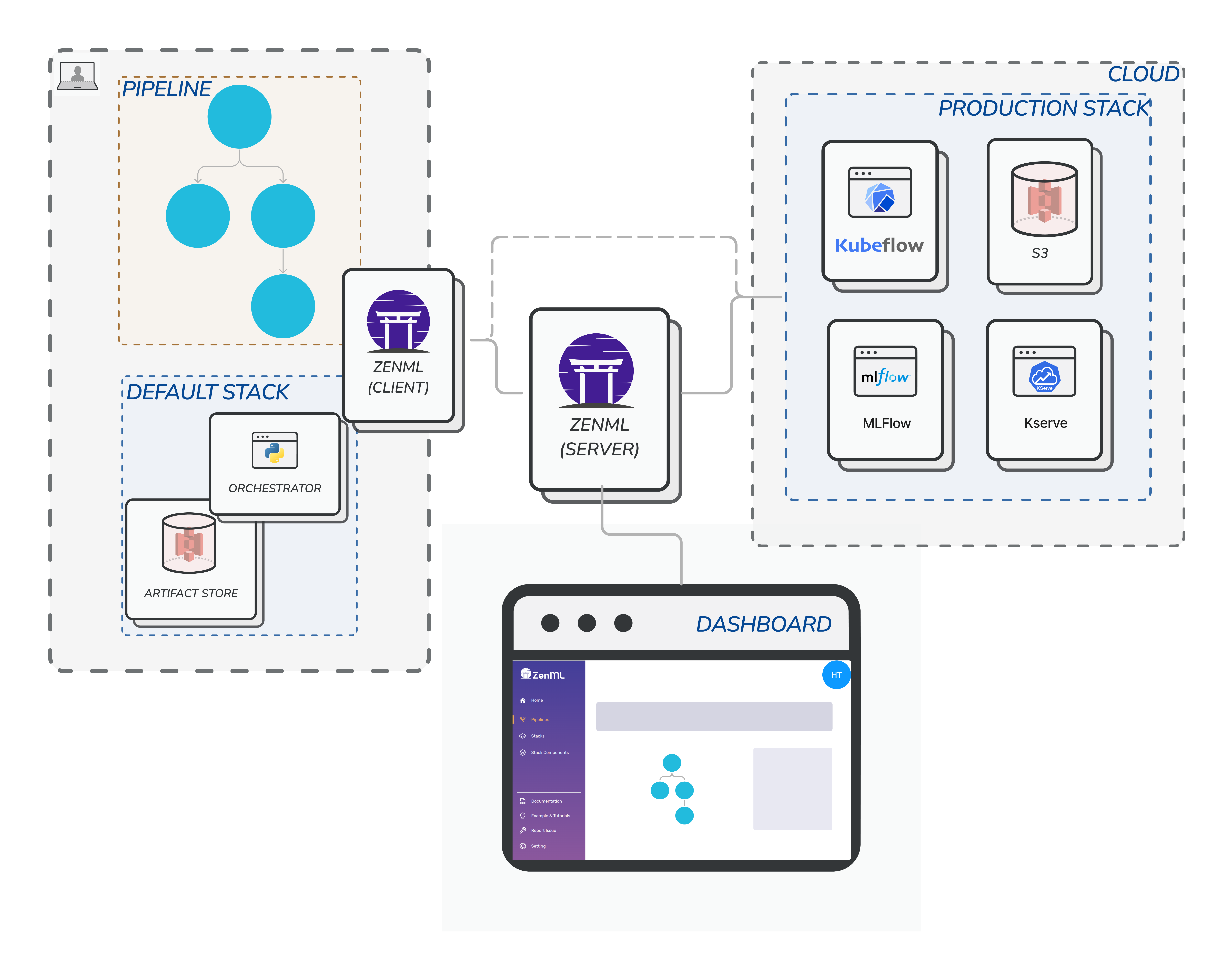
Other Bits and Pieces
There are lots of different ways to use ZenML which will depend on your precise use case. The following concepts and stack components are things you’ll possibly encounter further down the road while using ZenML.- Materializers - ZenML stores the data inputs and outputs to your steps in the Artifact Store as we saw above. In order to store the data, it needs to serialize everything in a format that can fit into the Artifact Store. ZenML handles serialization (and deserialization) of the most common artifacts, but if you try to do something we haven’t already thought of you’ll need to write your own custom materializer. This isn’t hard, but you should be aware that it’s something you might need do to. The ZenML CLI will let you know with a clear error message when you need to do this.
- Service - A service is a longer-lived entity that extends the capabilities of ZenML beyond the run of a pipeline. For example, a service could be a prediction service that loads models for inference in a production setting.
- Integrations - ZenML ships with many integrations into many MLOps tools for various use-cases, usually in the form of pre-made stack components or steps .